
Getting Started with Apache Kafka: Real-Time Data Streaming with Node.js
A Beginner's Guide to Understanding Kafka Architecture and Implementing it in Node.js Applications


💡 Introduction
In today’s data-driven world, the ability to process and analyze information in real-time is critical for businesses to stay competitive. Whether it’s tracking user activity, monitoring system health, or processing transactions, organizations need a reliable and scalable way to manage streams of data as they flow through their systems. This is where Apache Kafka comes into play. Originally developed by LinkedIn and later open-sourced as part of the Apache Software Foundation, Kafka has become the backbone of real-time data pipelines and streaming applications for companies of all sizes.In this blog, we'll explore the fundamentals of Apache Kafka and demonstrate how to integrate Kafka into a Node.js application. Whether you’re building a microservices architecture, implementing event-driven systems, or just curious about real-time data processing, this guide will help you get started with Kafka and leverage its powerful capabilities in your Node.js projects.
What is Kafka?
Apache Kafka is a distributed event streaming platform that allows you to publish, subscribe to, store, and process streams of records in real-time. At its core, Kafka is designed to handle large volumes of data by breaking it down into streams that can be processed in parallel. It acts as a high-throughput, low-latency platform for building real-time streaming data pipelines and applications that react to data as it.
It organizes data into topics, where each topic is a category to which records (messages) are sent. These topics can be partitioned to allow for horizontal scaling, meaning that as your data load increases, Kafka can grow with you, distributing the load across multiple servers in a Kafka cluster. This makes Kafka a go-to solution for applications that require reliable, scalable, and real-time data processing.
Why Kafka?
Kafka is widely adopted across industries for several compelling reasons:
Scalability: Kafka’s partitioned log model allows it to scale horizontally, making it capable of handling thousands of messages per second with low latency. This is crucial for modern applications that require quick and efficient data processing.
Fault Tolerance: Kafka is built to be resilient. It replicates data across multiple brokers in a cluster, ensuring that even in the event of hardware failure, your data remains safe and accessible.
Durability: Unlike traditional messaging systems, Kafka persists messages on disk, allowing consumers to read at their own pace. This makes Kafka suitable for applications where data durability is critical.
Flexibility: Kafka’s ability to decouple data producers and consumers allows for flexible and scalable architectures. It supports a wide range of use cases, from log aggregation and real-time analytics to event sourcing and stream processing.
💡 Kafka Architecture
Kafka Streams simplifies application development by building on the Kafka producer and consumer libraries and leveraging the native capabilities of Kafka to offer data parallelism, distributed coordination, fault tolerance, and operational simplicity.
Here is a picture to show the basic structure of Kafka Architecture:
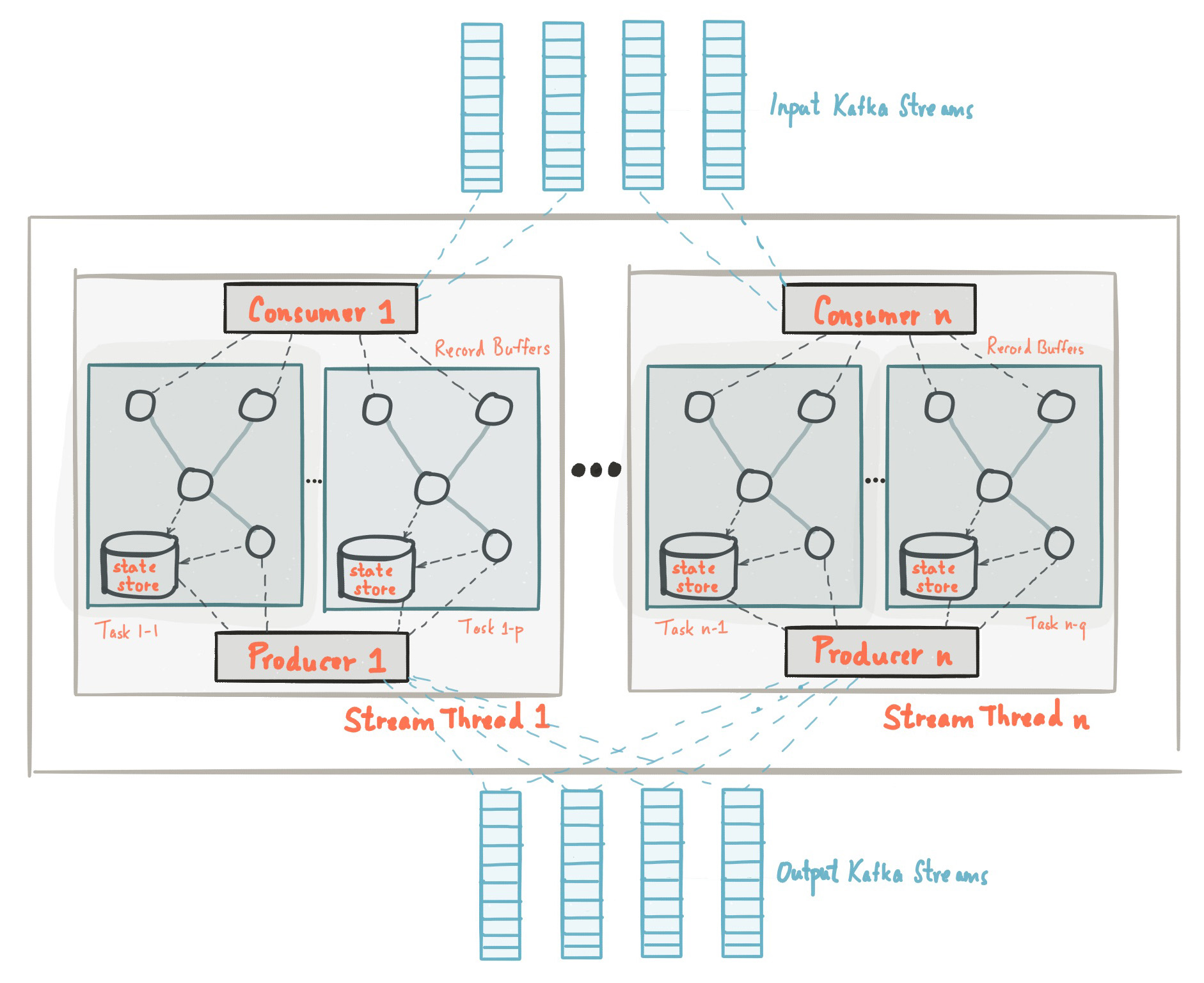
This diagram shows Consumers, producers, topics, zookeepers, etc. Below is a breakdown of these components and how they work together:
Kafka Broker
A Kafka broker is a server that handles the storage, management, and serving of data in Kafka topics. Kafka can run on a cluster of brokers, with each broker responsible for managing one or more partitions.
Brokers manage the lifecycle of partitions, store message logs, and serve read/write requests. Kafka’s ability to horizontally scale is driven by the fact that brokers can be added or removed from the cluster seamlessly.
Topics and Partitions
A topic is essentially a feed name to which messages are written. Each topic is divided into one or more partitions, which are smaller pieces of the topic that Kafka can distribute across brokers.
Partitions allow Kafka to scale horizontally. Each partition is an ordered sequence of records, and Kafka writes messages to them in a sequential log. Consumers can read from these partitions independently, allowing Kafka to support high throughput and parallel processing.
Producers
A producer is any application or system that sends (or “produces”) data to a Kafka topic. Producers push data to specific partitions of a topic.
Producers are responsible for deciding which partition to send messages to, either based on custom logic or using Kafka’s built-in partitioning strategy. This design ensures a load-balanced and scalable data ingestion process.
Consumers and Consumer Groups
Consumers are applications that read (or “consume”) data from Kafka topics. Consumers can subscribe to one or more topics and process the data in real time. A consumer group consists of multiple consumers working together to read data from a topic.
Consumers within the same group share the work of consuming data from partitions. Each partition is read by only one consumer in the group, ensuring load balancing. If a consumer fails, Kafka automatically reassigns the partitions it was consuming to another consumer in the group, which provides fault tolerance.
ZooKeeper
ZooKeeper is a distributed coordination service that Kafka uses to manage and coordinate the cluster, such as broker metadata, leader election, and partition assignments.
ZooKeeper is critical for managing the state of the Kafka cluster and ensuring that the system runs smoothly. For example, when new brokers are added or removed from the cluster, ZooKeeper helps Kafka manage the redistribution of data.
💡 Pre-requisties
Before diving into the setup and code, make sure you have the following tools and software installed on your system:
Docker: You'll need Docker to run both Kafka and Zookeeper in containers, which simplifies the setup process. You can download it from the official Docker website.
Node.js: This blog uses Node.js along with KafkaJS to create a producer-consumer application. Install Node.js from Node.js official site.
Yarn: Yarn is a package manager that we will use to manage dependencies. Install it globally by running:
npm install -g yarnVS Code: While any code editor will work, Visual Studio Code is highly recommended for its extensions and integrated terminal. You can download it from the Visual Studio Code website.
Once you have these prerequisites installed and set up, you’ll be ready to follow the rest of the blog and implement the Kafka-based application!
💡 Using Kafka in a NodeJS Application
In this project, we will create basic consumer and producer file showcasing the workflow of Kafka in which the producer will produce rider names and their location (either North or South) and it will be collected by consumer in different partitions. To start this project, create a new directory named "Node-Kafka-app" and run the following command in the directory:
cd Node-Kafka-app
yarn init
yarn add kafkajs
// consumer.js
const { kafka } = require("./client");
const group = process.argv[2];
async function init() {
const consumer = kafka.consumer({ groupId: group });
await consumer.connect();
await consumer.subscribe({ topics: ["rider-updates"], fromBeginning: true });
await consumer.run({
eachMessage: async ({ topic, partition, message, heartbeat, pause }) => {
console.log(
`${group}: [${topic}]: PART:${partition}:`,
message.value.toString()
);
},
});
}
init();
//producer.js
const { kafka } = require("./client");
const readline = require("readline");
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
async function init() {
const producer = kafka.producer();
console.log("Connecting Producer");
await producer.connect();
console.log("Producer Connected Successfully");
rl.setPrompt("> ");
rl.prompt();
rl.on("line", async function (line) {
const [riderName, location] = line.split(" ");
await producer.send({
topic: "rider-updates",
messages: [
{
partition: location.toLowerCase() === "north" ? 0 : 1,
key: "location-update",
value: JSON.stringify({ name: riderName, location }),
},
],
});
}).on("close", async () => {
await producer.disconnect();
});
}
init();
//admin.js
const { kafka } = require("./client");
async function init() {
const admin = kafka.admin();
console.log("Admin connecting...");
admin.connect();
console.log("Adming Connection Success...");
console.log("Creating Topic [rider-updates]");
await admin.createTopics({
topics: [
{
topic: "rider-updates",
numPartitions: 2,
},
],
});
console.log("Topic Created Success [rider-updates]");
console.log("Disconnecting Admin..");
await admin.disconnect();
}
init();
//client.js
const { Kafka } = require("kafkajs");
exports.kafka = new Kafka({
clientId: "my-app",
brokers: ["<PRIVATE_IP>:9092"],
});
// Change the PRIVATE_IP to your own IP Address.
These are basic code snippets that can be found on Kafka official website.
After creating all the files, we can run zookeeper in our docker which will act as an orchestrator to Kafka. Use the following command in your terminal to run zookeeper:
docker -d -p 2181:2181 zookeeper
# This will start zookeeper server in detach mode which will be listening on port 2181.
Then, Start the Kafka container which will expose on port 9092. Use the following command:
docker run -p 9092:9092 \
-e KAFKA_ZOOKEEPER_CONNECT=<PRIVATE_IP>:2181 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://<PRIVATE_IP>:9092 \
-e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
confluentinc/cp-kafka
# Remember to change thet PRIVATE_IP to your actual IP address
Now, the Zookeeper and Kafka server are running fine, don't close the terminal as it will stop the Servers. Create a new Terminal and run the following command to check Client connection to server:
cd /<App Directory>
node admin.js
This command will showcase this output:

After connecting the client to server, we can use our consumer.js file to save topics. Use the following command in Application directory to create consumer for kafka:
node consumer.js
Now, we have our consumer window open, create a new terminal and run the following command:
node producer.js
This will showcase this output:

Now it will prompt you to enter a RIDER-NAME and Its location(either NORTH or SOUTH).
Here is an example:

and if you check the logs of consumer.js file, you will see the following output:

Now, with help of Kafka, we can streamline our rider-names and location in two parts on basis of their location (north & south). All Riders of North location are stored in Partition 0 while riders of south are stored in Partition 1.
💡Conclusion
So, in this blog, we explored the foundational concepts of Apache Kafka, a distributed event streaming platform designed to handle real-time data processing at scale. We began by discussing the problems developers faced with traditional data handling methods, such as the inability to process large streams of data efficiently, which Kafka addresses with its high throughput, fault tolerance, and horizontal scalability. We then dived into Kafka's architecture, exploring key components like brokers, topics, partitions, producers, consumers, and ZooKeeper, which work together to deliver a robust data streaming solution. Finally, we demonstrated a simple Node.js application using KafkaJS to show how producers and consumers interact with Kafka to process and route data in real-time.
To watch a complete YT video on this project, here is the link.
Till then, Happy Coding!!